When I started using Claude I did what I think most people do — let it pick the model automatically and jumped straight in. Opus burned through my usage limit in ten minutes. I switched to Sonnet, which gets you further, but you’re still hitting the wall within an hour or two of heavy coding. Give Sonnet a project it can run with autonomously and it can exhaust a five-hour allowance in twenty minutes. Do that a few sessions in a row and you’ve burned your weekly limit before the week has really started.
I’m on the $20/month plan. If you’re on the $200 plan this probably isn’t a problem for you — but if you’re on the lower tier and finding that sessions burn out before the work is done, the fix comes down to one insight.
Output tokens cost significantly more than input tokens. The ratio varies by model — it isn’t always 5x — but the pattern holds across most of them. Reading is cheap. Generating is expensive.
The economics
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best for |
|---|---|---|---|
| Claude Opus | $5 | $25 | Hard architectural decisions |
| Claude Sonnet | $3 | $15 | Planning, review, decisions |
| Claude Haiku | $1 | $5 | Verification, targeted checks |
If a cheap model can produce output that’s 95% correct — because a more expensive model wrote the plan it’s working from — then you only need the expensive model to fix the 5% that’s wrong. The expensive model spends most of its tokens reading (cheap) rather than generating (expensive). That’s the whole game.
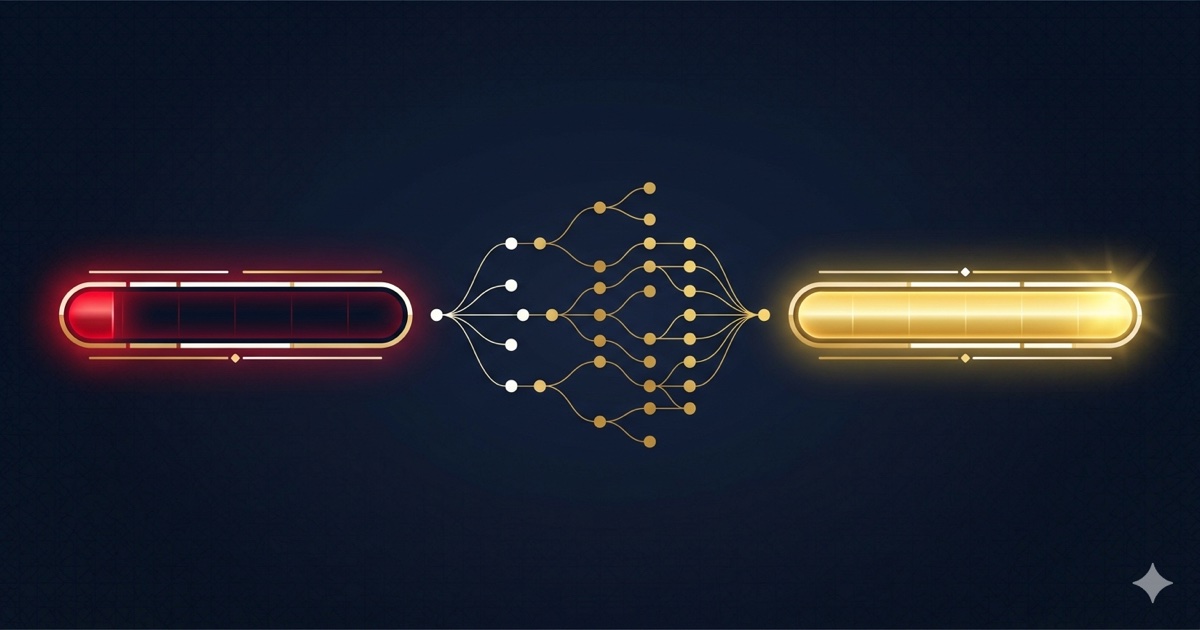
Single-model sessions are expensive because you’re paying Sonnet rates for every turn — planning, implementation, and review alike. Break the work up and each piece costs what it should.
The workflow
The structure is simple: Sonnet plans, Haiku builds, Sonnet fixes.
Sonnet (write plan)
→ Haiku subagents (implement plan in parallel)
→ Sonnet (review, fix off-spec work, update plan)
→ loopStep 1: Sonnet writes the plan
Before writing any code, ask Sonnet to produce a detailed implementation plan:
Review the codebase and write a detailed implementation plan for [feature/task]. Break it into discrete tasks that can be worked on independently. Cover what needs to be built, in what order, and what each piece needs to do. Save it to docs/PLAN.md.
The plan is the key artifact. Everything downstream gets measured against it — and since it’s written once and read many times, it’s the most cost-efficient thing Sonnet produces.
Step 2: Haiku implements with parallel subagents
Hand the plan to Sonnet and ask it to dispatch Haiku subagents to implement it:
Spawn parallel Haiku subagents to implement the plan in docs/PLAN.md. Assign each subagent a discrete task from the plan. Each subagent should read the relevant files, implement its task, and report back on what it did and any issues it encountered.
Haiku gets a fresh context for each task — it reads the plan, reads the relevant files, and implements. It doesn’t need to hold the whole session in memory, which is both cheaper and cleaner. Claude Code handles the orchestration.
Step 3: Sonnet reviews and fixes
Once the subagents report back, ask Sonnet to review and address anything that didn’t land:
Review what the Haiku subagents implemented against docs/PLAN.md. Fix anything that’s off-spec or incomplete. Then update docs/PLAN.md to reflect what was built and note what’s left for the next iteration.
Sonnet’s job here is reading and correcting — much lighter on output than if it had done the implementation itself. The updated plan becomes the input for the next loop.
A few things I’ve found
Haiku’s fresh context is a feature, not a limitation. A Haiku subagent checking a few files against a spec isn’t hampered by not knowing your session history — it’s better for not knowing. It reads what’s actually there rather than what a long session might lead you to assume.
Keep the plan as the source of truth. When Haiku’s implementation drifts from it, the plan is what you check against. Don’t let it become a living document that shifts with every implementation decision — that defeats the purpose.
Don’t ask Sonnet to implement and plan at the same time. The planning step is only valuable if it’s done before implementation starts. If you let Sonnet plan-as-it-goes, you lose the cost benefit and end up with a sprawling session anyway.
Going further
This workflow uses only Claude. If you want to push your usage even further, you can pull in external tools: Gemini’s free tier handles research and bulk implementation well, and Aider can drive implementation from the command line without touching your Claude session at all. But the Claude-only version above is enough to make a real difference on the $20 plan.
This post is part of a series on multi-model AI workflows. The companion post covers why Gemini and Claude think differently at the research stage — useful if you want to extend this into a full multi-model setup.
Have questions or want to share your own patterns? Find me on GitHub or LinkedIn.